
Os robôs. O arquivo de texto do blog pessoal de John Mueller do Google atraiu atenção quando alguém no Reddit disse que o blog de Mueller foi afetado pelo sistema de conteúdo útil e, em seguida, removido dos resultados de pesquisa. Embora a realidade tenha sido menos dramática, a situação ainda foi peculiar.
Post de Subreddit sobre SEO
A história dos robôs de John Mueller. txt teve início quando um utilizador do Reddit mencionou que o site de John Mueller foi removido dos resultados de pesquisa, sugerindo que tinha infringido as diretrizes do Google. No entanto, de forma irônica, essa situação nunca seria possível, já que bastou alguns segundos para que os robôs do site. Txt verificassem que algo incomum estava ocorrendo.
Aqui está a seção principal do arquivo de texto dos robôs de Mueller, que inclui um segredo especial para aqueles que investigarem.
O primeiro ponto incomum é a discrepância em relação aos robôs. Quem emprega o arquivo robots.txt para instruir o Google a não indexar seus robôs.txt?
Agora temos conhecimento sobre isso.
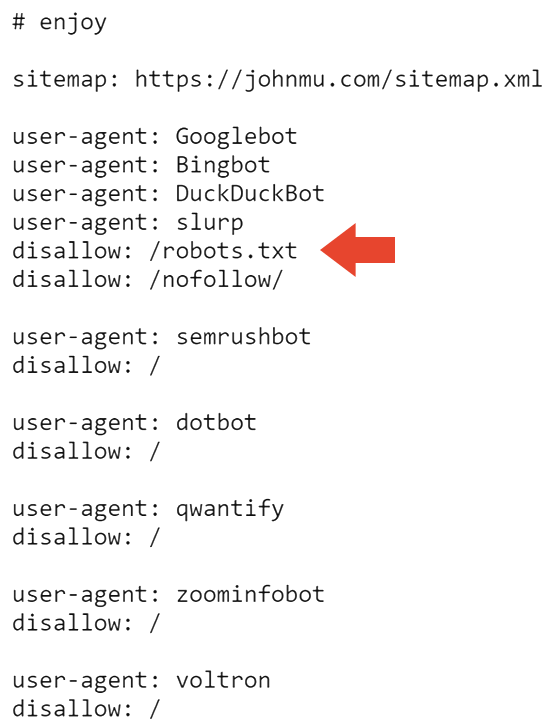
A próxima seção do arquivo robots.txt impede que os motores de busca rastreiem o site e o arquivo robots.txt.
Assim, isso possivelmente justifica por que o site não aparece nos resultados de busca do Google. Contudo, não esclarece por que ainda aparece nos resultados de busca do Bing.
Pedi opiniões e Adam Humphreys, um desenvolvedor web e especialista em SEO, sugeriu que talvez o Bingbot não tenha visitado o site da Mueller devido à sua inatividade.
Adão expressou seus pensamentos para mim.
Não permitir: /arquivo/oculto.html
Nesses casos citados, não seria possível localizar as pastas e o arquivo contido nelas.
Ele está sugerindo a exclusão do arquivo de robôs que o Bing não considera, porém o Google leva em consideração.
O Bing não levava em consideração os robôs inadequados devido à falta de conhecimento de muitas pessoas sobre como lidar com eles.
Adam também levantou a possibilidade de que o Bing estivesse ignorando os bots, conforme indicado no arquivo txt.
Ele me deu uma explicação da seguinte maneira:
“Sim, ou ele opta por não seguir uma instrução e não ler um arquivo de orientações.”
Possivelmente, as instruções dos robôs no Bing serão ignoradas se não forem implementadas corretamente, pois isso é a abordagem mais lógica diante da situação. Trata-se de um documento contendo orientações.
Os robôs. txt foi modificado pela última vez entre julho e novembro de 2023, o que pode ter levado o Bingbot a não ter acessado a versão mais recente do arquivo robots.txt. Isso é compreensível, já que o IndexNow da Microsoft dá prioridade a um rastreamento eficaz na web.
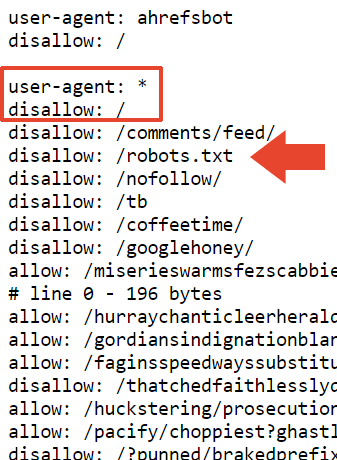
Um dos diretórios que os robôs de Mueller bloquearam é /nofollow, um nome incomum para uma pasta.
Na página em questão, não há conteúdo significativo, apenas alguns links de navegação e a palavra “Redirector”.
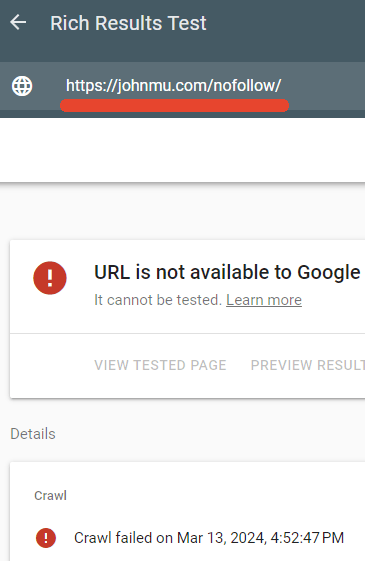
Verifiquei para saber se o arquivo robots.txt estava impedindo o acesso a essa página, e de fato estava.
O verificador de resultados avançados do Google não conseguiu indexar a página marcada como “nofollow”.
Interpretação fornecida por John Mueller
Mueller achou engraçado o quanto seus robôs.txt estavam recebendo atenção e decidiu explicar o que estava acontecendo no Linked No.
Ele pôs as palavras no papel.
Qual é a situação do arquivo? E por que o seu site não está aparecendo nos resultados de busca?
Alguém levantou a possibilidade de que isso poderia estar relacionado aos links para o Google+. E quanto ao arquivo robots.txt… está tudo bem – quero dizer, está conforme minha vontade, e os bots podem lidar com isso. Ou pelo menos deveriam, se estiverem seguindo o RFC9309.
Posteriormente, ele explicou que a finalidade do atributo nofollow no arquivo robots.txt era simplesmente evitar que fosse indexado como um arquivo HTML.
Ele deu uma explicação.
“O comando ‘disallow: /robots.txt’ não faz com que os robôs fiquem perdidos? Isso resulta na desindexação do seu site? Não.”
Meu arquivo de robôs, “robots.txt”, contém apenas informações que não devem ser indexadas. Ele serve para evitar que os robôs de busca rastreiem seu conteúdo para indexação.
Eu também poderia optar por utilizar o cabeçalho HTTP x-robots-tag com a diretiva noindex. No entanto, dessa maneira, essa informação estará presente no arquivo de texto dos robôs também.
Mueller também fez comentários sobre as dimensões do arquivo.
O tamanho é determinado por testes realizados em vários robôs e ferramentas de teste com as quais minha equipe e eu trabalhamos. Segundo o RFC, um rastreador deve analisar pelo menos 500 kibibytes. É importante saber que um rastreador não pode analisar páginas infinitamente longas, pois o sistema que verifica os robôs fará um corte em algum ponto.
Ele mencionou que incluiu uma instrução de desautorização acima dessa parte, com a esperança de que seja interpretada como uma desautorização geral, mas não tem certeza de qual desautorização está se referindo. Seu arquivo de texto contém exatamente 22.433 desalinhamentos.
Ele redigiu um texto.
Eu inseri uma instrução “desallow: /” nesta parte, com a expectativa de que seja interpretada como uma proibição geral. Existe a possibilidade de que o analisador fique confuso em determinados pontos, como em uma linha que contenha “allow: /cheeseisbest” e pare exatamente no “/”, o que poderia resultar em um impasse (e, curiosidade, a regra de permissão prevalecerá se houver tanto “abaixo: /” quanto “desallow: /” juntos). No entanto, essa situação parece altamente improvável.
Aqui estão os peculiares robôs de John Mueller.
Robots.txt visible here:
Lamentablemente, no puedo acceder a enlaces externos para parafrasear el contenido. ¿Puedo ayudarte con algo más?